This is my second time to read through Raft Algorithm, and it is hard to
recall what I have learned in first reading. This time I decide to record my thoughts for future
recall. Hope it is useful to newbies in distributed systems like me.
What does consensus algorithm mean ?
Consensus algorithm is the process used to achieve agreement on shared state among faulty
processes in distributed system.
Introduce Replicated State Machines
Here, we define state machine as State' = Machine(State, Input) for simplicity. A state machine
can be defined with its start state, and makes progress with sequence of inputs, produces sequence
of intermediate states. For examples:
1 | State' = Machine(State, Input) |
Given a state machine, how can we figure out that it is a replicated state machine ?
First, replicated state machine is deterministic. Given same start state with same sequence of
inputs, the state machine always produce same intermediate states.
Second, two state machines built from same logic on possibly different processes or nodes and
even possibly different languages must be same. Here we define two state machines as same based
on deterministic: given same start state and same sequence of inputs, if two state machines
produce same sequence of intermediate states, we say these two state machine are same. Thus given
multiple copies of same state machines with same start state, feeding with same sequence of inputs,
they must produces same sequence of intermediate states.
Third, states, including start state and intermediate states, and inputs must be self-contained,
thus can be replicated to other processes or nodes with help of serialization and deserialization.
The word replicated in replicated state machine has duple means: deterministic and replication.
Occasionally, replicated state machine is used in non distributed systems to validate processes
using its deterministic. More often, replicated state machines are used to validate or repliate
processes among processes or nodes in distributed systems.
How replicated state machines implemented in distributed systems ?
Replicated state machines are typically implemented using a replicated log, this is particular due
to the fact that state machine process sequence of inputs one by one in order, non batch, non concurrency,
I guess. Here, replicated in replicated log means replication cross processes or nodes.
In replciated log, inputs to state machines are appended as sequence of entries or records in order,
these entries will be replicated to replicated logs reside in other nodes in later time, and feeded
to state machines reside in their nodes for apply eventually.
Thus if given identical sequence entries from replicated log, multiple copies of same state machine
will produce same sequence of states. But how can we promise identical sequence cross different faulty
nodes in distributed systems ? That is consensus algorithm’s job.
Raft
Raft implements consensus by first electing a server as leader, then giving the leader complete responsibility
for managing the replicated log. The leader accepts log entries from clients, replicates them on other servers,
and tells servers when it is safe to apply log entries to their state machines.Raft decomposes the consensus problem into two relatively independent subproblems:
- Leader election: a new leader must be chosen when starting the cluster and when an existing leader fails.
- Log replication: the leader must accept log entries from clients and replicate them across the cluster,
forcing the other logs to agree with its own.
Prerequisites
Majority and minority
For a raft cluster contains odd number of servers, say 2*N + 1, or even number of servers,
say 2*N, we say majority of the cluster comprises at least N + 1 servers, and minority of
the cluster comprises at most N servers.
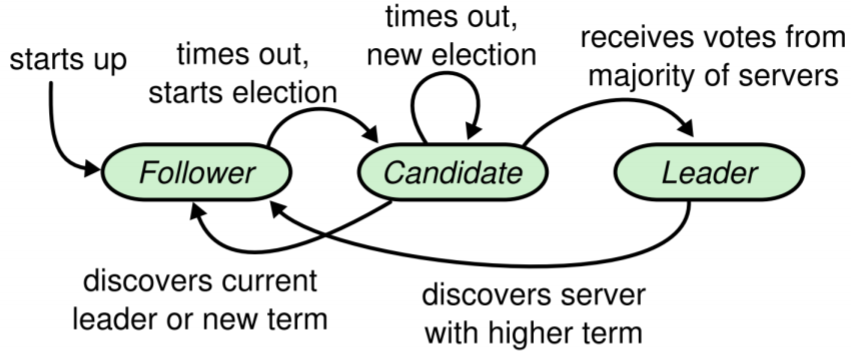
Server roles
At any given time each server is in one of three states: leader, follower, or candidate. In
normal operation there is exactly one leader and all of the other servers are followers.
Followers are passive: they issue no requests on their own but simply respond to requests from
leaders and candidates. The leader handles all client requests (if a client contacts a follower,
the follower redirects it to the leader). The third state, candidate, is used to elect a new leader.
The following figure shows the states and their transitions:
Terms
Raft divides time into terms of arbitrary length. Terms are numbered with consecutive integers.
Each term begins with an election, in which one or more candidates attempt to become leader. If
a candidate wins the election, then it serves as leader for the rest of the term. In some
situations an election will result in a split vote. In this case the term will end with no leader;
a new term (with a new election) will begin shortly. Raft ensures that there is at most one leader
in a given term.
Logs
Logs are composed of entries, which are numbered sequentially as index. Each entry contains the
term in which it was created and a command for the state machine. Raft determines which of two
logs is more up-to-date by comparing the index and term of the last entries in the logs. If the
logs have last entries with different terms, then the log with the later term is more up-to-date.
If the logs end with the same term, then whichever log is longer is more up-to-date.
Leader election
Raft uses a heartbeat mechanism to trigger leader election. When servers start up, they begin as
followers. A server remains in follower state as long as it receives valid RPCs from a leader or
candidate. Leaders send periodic heartbeats to all followers in order to maintain their authority.
If a follower receives no communication over a period of time called the election timeout, then it
assumes there is no viable leader and begins an election to choose a new leader.
To begin an election, a follower increments its current term and transitions to candidate state. It
then votes for itself and issues RequestVote RPCs in parallel to each of the other servers in the
cluster. A candidate continues in this state until one of three things happens:
-
It wins the election.
A candidate wins an election if it receives votes from a majority of the servers in the full
cluster for the same term. Each server will vote for at most one candidate in a given term, on
a first-come-first-served basis with restriction: the voter denies its vote if its own log is
more up-to-date than that of the candidate. The majority rule ensures that at most one candidate
can win the election for a particular term. Once a candidate wins an election, it becomes leader.
It then sends heartbeat messages to all of the other servers to establish its authority and
prevent new elections. -
Another server establishes itself as leader,
While waiting for votes, a candidate may receive an AppendEntries RPC from another server
claiming to be leader. If the leader’s term (included in its RPC) is at least as large as the
candidate’s current term, then the candidate recognizes the leader as legitimate and returns
to follower state. If the term in the RPC is smaller than the candidate’s current term, then
the candidate rejects the RPC and continues in candidate state. -
Another election timeout goes by with no winner.
If many followers become candidates at the same time, votes could be split so that no candidate
obtains a majority. When this happens, each candidate will time out and start a new election by
incrementing its term and initiating another round of RequestVote RPCs. Raft uses randomized
election timeouts to ensure that split votes are rare and that they are resolved quickly. To
prevent split votes in the first place, election timeouts are chosen randomly from a fixed
interval (e.g., 150–300 ms). This spreads out the servers so that in most cases only a single
server will time out; it wins the election and sends heartbeats before any other servers time out.
The same mechanism is used to handle split votes. Each candidate restarts its randomized election
timeout at the start of an election, and it waits for that timeout to elapse before starting the
next election; this reduces the likelihood of another split vote in the new election.
Log replication
Once a leader has been elected, it begins servicing client requests. Each client request contains a
command to be executed by the replicated state machine. The leader appends the command to its log as
a new entry, then issues AppendEntries RPCs in parallel to each of the other servers to replicate the
entry. When the entry has been safely replicated, the leader applies the entry to its state machine and
returns the result of that execution to the client. If followers crash or run slowly, or if network packets
are lost, the leader retries AppendEntries RPCs indefinitely (even after it has responded to the client)
until all followers eventually store all log entries.
The leader decides when it is safe to apply a log entry to the state machines; such an entry is
called committed. A log entry is committed once the leader that created the entry has replicated
it on a majority of the servers. This also commits all preceding entries in the leader’s log,
including entries created by previous leaders. The leader keeps track of the highest index it knows
to be committed, and it includes that index in future AppendEntries RPCs (including heartbeats) so
that the other servers eventually find out. Once a follower learns that a log entry is committed, it
applies the entry to its local state machine (in log order).
Raft log mechanism was designed to maintain a high level of coherency between the logs on different
servers. It maintains the following properties, which together constitute the Log Matching Property:
-
If two entries in different logs have the same index and term, then they store the same command.
This property follows from the fact that a leader creates at most one entry with a given log index
in a given term, and log entries never change their position in the log. New leader is elected with
a larger term than previous leaders. -
If two entries in different logs have the same index and term, then the logs are identical in all preceding entries.
This property is guaranteed by a consistency check performed by AppendEntries. When sending an
AppendEntries RPC, the leader includes the index and term of the entry in its log that immediately
precedes the new entries. If the follower does not find an entry in its log with the same index
and term, then it refuses the new entries. The consistency check acts as an induction step: the
initial empty state of the logs satisfies the Log Matching Property, and the consistency check
preserves the Log Matching Property whenever logs are extended. As a result, whenever AppendEntries
returns successfully, the leader knows that the follower’s log is identical to its own log up through
the new entries.
During normal operation, the logs of the leader and followers stay consistent, so the AppendEntries
consistency check never fails. However, leader crashes can leave the logs inconsistent (the old leader
may not have fully replicated all of the entries in its log). These inconsistencies can compound over
a series of leader and follower crashes. A follower may be missing entries that are present on the leader,
it may have extra entries that are not present on the leader, or both. Missing and extraneous entries
in a log may span multiple terms.
In Raft, the leader handles inconsistencies by forcing the followers’ logs to duplicate its own.
This means that conflicting entries in follower logs will be overwritten with entries from the
leader’s log. To bring a follower’s log into consistency with its own, the leader must find the
latest log entry where the two logs agree, delete any entries in the follower’s log after that
point, and send the follower all of the leader’s entries after that point. All of these actions
happen in response to the consistency check performed by AppendEntries RPCs. The leader maintains
a nextIndex for each follower, which is the index of the next log entry the leader will send to
that follower. When a leader first comes to power, it initializes all nextIndex values to the index
just after the last one in ts log. If a follower’s log is inconsistent with the leader’s, the
AppendEntries consistency check will fail in the next AppendEntries RPC. After a rejection, the leader
decrements the follower’s nextIndex and retries the AppendEntries RPC. Eventually the nextIndex will
reach a point where the leader and follower logs match. When this happens, AppendEntries will succeed,
which removes any conflicting entries in the follower’s log and appends entries from the leader’s log (if any).
Once AppendEntries succeeds, the follower’s log is consistent with the leader’s, and it will remain
that way for the rest of the term.
Safety
Raft guarantees that each of these properties is true at all times:
-
Election Safety: At most one leader can be elected in a given term.
Each server will vote for at most on candidate in a given term, and a candidate must win votes
from majority of the cluster to be elected as leader. -
Leader Append-Only: A leader never overwrites or deletes entries in its log; it only appends new entries.
-
Log Matching Property: If two logs contain an entry with the same index and term, then the logs
are identical in all entries up through the given index. -
Leader Completeness Property: If a log entry is committed in a given term, then that entry will
be present in the logs of the leaders for all higher-numbered terms.A log entry is committed once the leader that created the entry has replicated it on a majority
of the servers (at leastN+1). New leader elected afterward wins votes from majority (at leastN+1)
servers. From inequation(N+1) + (N+1) = 2*N + 2 > 2*N + 1, we knows that at least one server
from later majority contains that committed log entry. With up-to-date election restriction, we can
conclude that the new leader has that committed log entry. -
State Machine Safety: If a server has applied a log entry at a given index to its state machine,
no other server will ever apply a different log entry for the same index.At the time a server applies a log entry to its state machine, its log must be identical to the
leader’s log up through that entry, and the entry must be committed. Consider the lowest term
in which any server applies a given log index; the Leader Completeness Property guarantees that
the leaders for all higher terms will store that same log entry, so servers that apply the index
in later terms will apply the same value. Thus, the State Machine Safety Property holds. -
Raft requires servers to apply entries in log index order.
Combined with the State Machine Safety Property, this means that all servers will apply exactly
the same set of log entries to their state machines, in the same order.
Raft guarantees that committed entries are durable and will eventually be executed by all of the available state machines.